Home . Projects . Research . Publications . Members . Demos
Huge and increasing amount of videos broadcast through networks has raised the need of automatic video copy detection for copyright protection. Recent developments in multimedia technology introduced content-based copy detection (CBCD) as a new research field alternative to the watermarking approach for identification of video sequences.

With the rapid development of multimedia technologies and media-streaming, copyrighted materials become easily copied, stored, and distributed over the Internet. This situation, aside from enabling users to access information easily, causes huge piracy issues. One possible solution to identify copyrighted media is watermarking.
Digital watermarking was proposed for copyright protection and finger-printing. The basic idea is to embed an information into the signal of the media (audio, video, or photo). Some watermarks are visible (e.g., text or logo of the producer or broadcaster), while others are hidden in the signal, which cannot be perceived by human eye. Today all DVD movies, video games, audio CDs, etc. have fingerprints that prove the ownership of the material.
As a disadvantage, watermarks are generally fragile to visual transformations (e.g., re-encoding, change of the resolution/bit rate). For example, hidden data embedded on a movie will probably be lost when the clip is compressed and uploaded to a video sharing web site. Besides, temporal information of the video segments (e.g., frame number, time-code) are also important in some applications. Watermarking technique is not designed to be used for video retrieval by querying with a sample video clip.
Content-based copy detection (CBCD) is introduced as an alternative, or in fact, a complementary research field to watermarking approach. The main idea of CBCD is that the media visually contains enough information for detecting copies. Therefore, the problem of content-based copy detection is considered as video similarity detection by using the visual similarities of video clips.
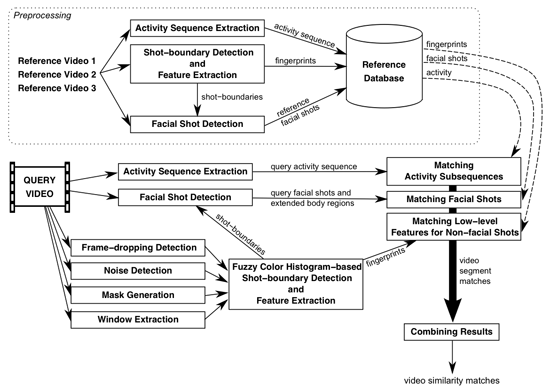
Our aim is to propose a multimodal framework for content-based copy detection and video similarity detection. The proposed method consists of three parts: First, a high-level face detector identifies facial frames/shots in a video clip. Matching faces with extended body regions gives the flexibility to discriminate the same person (e.g., an anchor man or a political leader) in different events or scenes. In the second step, a spatiotemporal sequence matching technique is employed to match video clips/segments that are similar in terms of activity. Finally the non-facial shots are matched using low-level visual features.